👀2주차 220117 ~ 220123 공부기록
📍 본 포스팅은 <혼자 공부하는 머신러닝+딥러닝> 책을 바탕으로 작성함을 알립니다.
✅Ch.03-3 특성 공학과 규제
🔥특성공학(feature engineering)
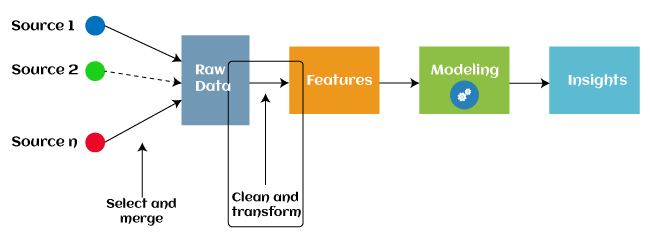
특성 공학(Feature engineering)은 머신러닝의 pre-processing 단계로, 기존의 데이터로부터 새로운 특성을 추출하는 작업을 의미한다. Feature engineering은 더 좋은 방법으로 예측 모델에서 근본적인 문제를 나타내도록 돕는다. 결과적으로 보이지 않는 데이터로부터 모델의 정확성을 향상시킨다. 머신러닝에서 Feature engineering은 주로 4가지의 과정(Feature Creation, Transformation, Feature Extraction, and Feature Selection)을 거친다. 본 포스팅은 사이킷런을 이용하여 Transformation을 보여주기 때문에, 더 많은 설명을 원한다면, 본 포스팅 하단의 참고자료를 참고하면 된다.
Feature engineering의 목표
1. 머신러닝 알고리즘에 걸맞는 적당한 입력 데이터셋을 준비
2. 머신 러닝 모델의 성능을 향상시키는 것이다.
Feature engineering을 사용하는 이유
과적합과 편향을 방지하기 위해서이다. 과적합을 방지하는 이유는 불필요한 요소들이 분석에 사용될 경우 과적합이 발생하여 테스트 세트가 제대로 동작하지 않거나, 모델이 단순해질 수 있기 때문이다. 편향 방지를 하는 이유는 부정확한 정보들이 분석에 적용될 경우 편향이 발생하기 때문이다.
+) 데이터가 방대하다고 해도 그 데이터를 모두 결과를 도출하는데 쓰면 정확히 나타날 듯하지만 오히려 결과를 잘못되게 도출하는 경우가 많다. 이는 통계분석에서 선형 함수의 독립변수가 많다고 해서 종속변수의 기대값의 정확도가 무조건 올라가지 않는 이유라고도 할 수 있다. 즉, 머신 러닝의 성능은 어떤 데이터를 입력하는지가 굉장히 의존적이다. 가장 이상적인 입력 데이터는 부족하지도 과하지도 않은 정확한 정보만을 포함될 때이다. 그래서 Feature engineering단계를 거쳐 입력 데이터를 추출해야한다.
Feature engineering의 중요성
데이터의 특성은 사용하는 예측 모델과 목표하는 결과에 직접적으로 영향을 미친다. 그렇기 때문에 데이터에서 더 나은 특성을 추출할 필요가 있다.
1. Better features means flexibility. The flexibility of good features will allow you to use less complex models that are faster to run, easier to understand and easier to maintain.
2. Better features means simpler models. With well engineered features, you can choose “the wrong parameters” (less than optimal) and still get good results, for much the same reasons. You do not need to work as hard to pick the right models and the most optimized parameters. With good features, you are closer to the underlying problem and a representation of all the data you have available and could use to best characterize that underlying problem.
3. Better features means better results. As already discussed, in machine learning, as data we will provide will get the same output. So, to obtain better results, we must need to use better features.
❓어떻게 변환을 하나요?
사이킷런을 이용하여 사이킷런의 클래스인 변환기를 부른다. 본 포스팅에서 사용할 변환기는 PolynominalFeatures 클래스이다. (변환기는 타깃 데이터 없이 입력 데이터를 변환한다.)
아래 코드의 결과를 보자. 2개의 특성([2, 3])을 훈련시키고 변환시키면, [1. 2. 3. 4. 6. 9]라는 결과를 볼 수 있다. 이 결과가 즉 2개의 특성을 변환한 값이다. 결과는 2와 3을 이용하여 각 특성을 제곱한 항과 특성끼리 서로 곱한 항을 추가하였다. 1은 선형 방적식의 절편에 항상 곱해지는 계수라고 볼 수 있다.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit([[2,3]])
print(poly.transform([[2,3]]))
#[[1. 2. 3. 4. 6. 9.]]
(사이킷런 모델은 자동으로 특성에 추가된 절편 항을 무시하지만, 헷갈린다면 명시적으로 1을 없앨 수 있다. 1을 없애는 방법은 include_bias=False를 지정하면 된다. 만약 include_bias=True라면 거듭제곱 항은 제외되고 특성 간의 곱셈 항만 추가된다. 기본값은 False이다.)
#include_bias=False 지정
poly = PolynomialFeatures(include_bias=False)
#[[1. 2. 3. 4. 6. 9.]]앞서 설명한 내용이지만, 변환하는 방법을 정리하자면
1️⃣ PolynominalFeatures 클래스를 임포트한다.
2️⃣ 변환기 클래스가 제공하는 fit(), transform() 메서드를 차례대로 호출한다. (변환)
3️⃣ 잘 변환되었는지 훈련 세트와 테스트 세트로 확인한다. shape() 메서드를 이용하여 배열의 크기로 확인하면 된다.
(42, 9)를 보면 9개의 특성을 만들었다.(3개의 특성을 사용하였다. train_input안에 3개의 특성을 넣었음) 9개의 특성이 각각 어떤 입력의 조합으로 만들어졌는지 알고 싶다면 get_feature_names()메서드를 이용하면 된다.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
print(train_poly.shape) #훈련데이터
#(42, 9)
#테스트 데이터
test_poly = poly.transform(test_input)
#(14, 9)
#9개의 특성이 어떤 조합으로 이루어졌는지
poly.get_feature_names()
#['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2']📍Transformations: The transformation step of feature engineering involves adjusting the predictor variable to improve the accuracy and performance of the model. For example, it ensures that the model is flexible to take input of the variety of data; it ensures that all the variables are on the same scale, making the model easier to understand. It improves the model's accuracy and ensures that all the features are within the acceptable range to avoid any computational error.
🔥규제(regularization)
규제(regularization)는 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말한다. 즉 모델이 훈련세트에 과대적합되지 않도록 만드는 것이다. 선형 회귀 모델의 경우 특성에 곱해지는 계수(또는 기울기)의 크기를 작게 만드는 일이다. 하단의 그림에서 좌측은 훈련세트를 과도하게 학습한 그래프이고 우측은 규제를 통해 보편적인 패턴으로 학습한 것이다.
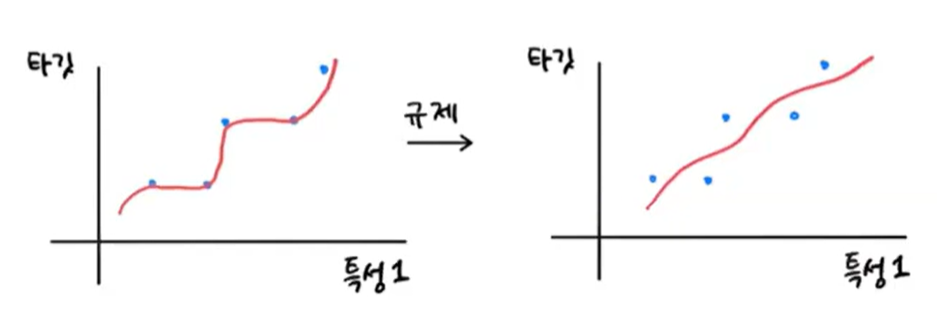
❗특성의 스케일 정규화
특성의 스케일이 정규화되지 않는다면 곱해지는 계수 값도 차이가 나게 되기 때문에 규제를 하기 전에 정규화를 해주어야 한다. 정규화를 해주는 방법 중 하나는 사이킷런의 변환기 클래스를 사용하는 것이다.
❓정규화를 하는 방법
1️⃣사이킷런에서 제공하는 StandardScaler 클래스를 임포트 후 클래스의 객체 ss를 만든다.
2️⃣PolynominalFeatures 클래스로 만든(변환시킨) train_poly를 사용하여 객체를 훈련시킨다.
3️⃣훈련 세트에 적용했던 변환기로 테스트 세트에도 적용하여 표준점수로 변환해 준다.
*) 표준점수(z점수)는 가장 널리 사용하는 전처리 방법 중 하나이다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
#표준점수로 변환한 훈련세트와 테스트 세트
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)선형 회귀 모델에 규제를 추가한 모델을 릿지(ridge)와 랏쏘(lasso)라고 부른다. 두 모델은 규제를 가하는 방법이 다르다. 릿지는 계수를 제곱한 값을 기준으로 규제를 적용하고, 라쏘는 계수의 절댓값을 기준으로 규제를 적용한다. 두 알고리즘 모두 계수의 크기를 줄이지만 라쏘는 아예 계수를 0으로 만들 수 있기 때문에 릿지를 일반적으로 조금 더 선호하는 편이다.
🔥릿지 회귀 (L2 Regression, Ridge regression)
릿지 회귀는 규제가 있는 선형 회귀 모델 중 하나이며, 선형 모델의 계수를 작게 만들어 과대적합을 완화시킨다. 릿지는 비교적 효과가 좋아 널리 사용하는 규제 방법이다.
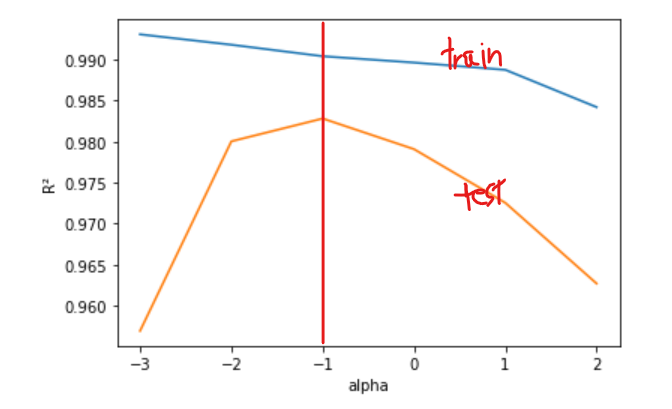
* 규제의 강도를 임의로 조절하기 위해 alpha 매개변수를 사용한다. alpha 값이 클수록 규제가 세지고 기본값은 1이다. 적절한 alpha값을 찾는 한 가지 방법은 alpha값에 대한 R²값의 그래프를 그리는 것이다. 훈련세트와 테스트 세트의 점수가 가장 가까운 지점이 최적의 alpha값이 된다.
(* 하이퍼 파라미터 : 머신러닝 알고리즘이 학습하지 않는 파라미터이다. 이런 파라미터는 사람이 사전에 지정해야 한다. 대표적으로 릿지와 라쏘의 규제 강도 alpha 파라미터이다. 머신러닝 모델이 특성해서 학습한 모델 파라미터와는 정반대의 개념이다.)
❗적절한 alpha값을 찾기 위해 R²값의 그래프를 그리기
alpha값을 바꿀 때마다 score() 메서드의 결과를 저장할 리스트를 만들고 alpha값을 10배씩 늘려가며 릿지 회귀 모델 훈련을 한다. 그 후 훈련 세트와 테스트 세트의 점수를 파이썬 리스트에 저장한다.
#ridge모델 훈련
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
#alpha값을 바꿀 때마다 score() 메서드의 결과를 저장할 리스트
import matplotlib.pyplot as plt
train_score = []
test_score = []
#alpha값을 0.001애서 100까지 10배씩 늘려가며 릿지 회귀 모델 훈련
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
#릿지 모델 만들기
ridge = Ridge(alpha=alpha)
#릿지 모델 훈련
ridge.fit(train_scaled, train_target)
#훈련 점수와 테스트 점수를 저장
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
#그래프그리기 주의_로그함수로 바꿔 지수로 표현하기
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R²')
plt.show()위는 훈련 세트 그래프, 아래는 테스트 세트 그래프이다. 적절한 alpha값은 두 그래프가 가장 가깝고 테스트 점수가 가장 높은 -1, 즉 10⁻¹=0.1이다.
🔥라쏘 회귀 (L1 Regression, Lasso regression)
Lasso는 규제가 있는 회귀 알고리즘인 라쏘 회귀 모델을 훈련한다. 이 클래스는 최적의 모델을 찾기 위해 좌표축을 따라 최적화를 수행해가는 좌표 하강법(coordinate descent)을 사용한다. 릿지와 달리 계수 값을 아예 0으로 만들 수도 있다.
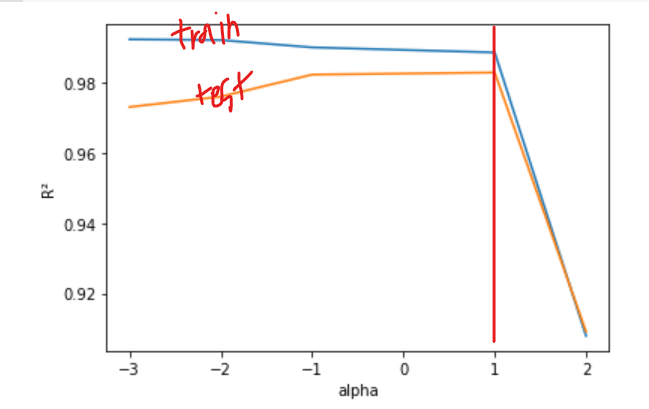
❗적절한 alpha값을 찾기 위해 R²값의 그래프를 그리기
Lasso 모델을 훈련하는 것은 Ridge와 매우 비슷하다. Ridge모델과 같이 Lasso 또한 적절한 alpha값을 바꾸어가며 규제의 강도를 조절한다.
#lasso 모델 훈련
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 10, 100]
for alpha in alpha_list:
#라쏘 모델을 만듭니다.
lasso = Lasso(alpha=alpha, max_iter=10000)
#라쏘 모델을 훈련합니다.
lasso.fit(train_scaled, train_target)
#훈련 점수와 테스트 점수를 저장
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))
#그래프 그리기
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R²')
plt.show()Lasso 모델에서 최적의 alpha값은 1, 즉 10¹=10 이다.
❓라쏘 모델이 릿지와 달리 계수 값을 아예 0으로 만들 수도 있다는 것은 무슨 뜻인가요?
#라쏘 모델 계수 중 0인 것 추려내기
print(np.sum(lasso.coef_ == 0))
#40라쏘 모델의 계수는 coef_속성에 저장되어 있다. 이 중 0인 것을 헤아리면 40개가 된다는 것을 알 수 있다. 55개의 특성을 모델에 주입했지만 라쏘 모델이 사용한 특성은 15개밖에 되지 않는다. 이처럼 라쏘 모델은 계수 값을 아예 0으로 만들어 낼 수 있다. 이런 특징 때문에 라쏘 모델을 유용한 특성을 골라내는 용도로도 사용할 수 있다.
* ) 라쏘 회귀는 파라미터의 크기에 관계없이 같은 수준의 Regularization을 적용하기 때문에 작은 값의 파라미터를 0으로 만들어 해당 변수를 삭제하고 따라서 모델을 단순하게 만들어주고 해석에 용이하게 만들어준다.
💡다중 회귀(multiple regression)
여러 개의 특성을 사용한 선형 회귀 모델이다. 특성이 많으면 선형 모델은 강력한 성능을 발휘한다. 고려해야하는 변수가 많기 때문에 인간의 생각과 상상으로는 불가능하다. 하단의 이미지와 같이 특성 2개만을 사용하여 3차원 공간을 형성할 수있지만, 그 이상은 불가능하기에 다중 회귀를 이용한다.
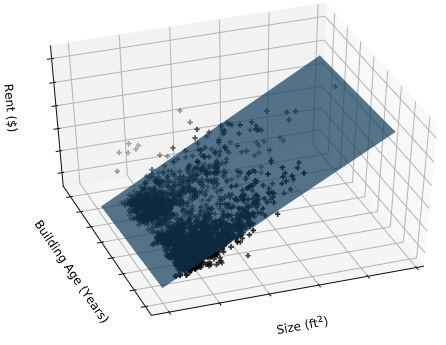
* )다중 선형 회귀의 예측 함수이다. 특성은 총 p+1개, 그에 따라 가중치도 p+1개이다. 주어진 여러 샘플들의 p+1개의 특징(x[0]~x[p])과 라벨값(y) 사이의 관계를 잘 나타내주는 w와 b를 찾아야 한다. 특징이 1개인 선형회귀에선 모델이 직선이었지만, 2개면 평면이 되고, 그 이상이면 초평면(hyperplane)이 된다.
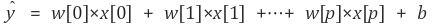
+) 다향회귀(polynomial regression) : 다항식을 사용하여 특성과 타깃 사이의 관계를 나타내는 회귀. 다중회귀와 다항회귀는 엄연히 다르게 때문에 헷갈리지 말도록 하자.
💡판다스(pandas)
판다스는 유명한 데이터 분석 라이브러리이다. 데이터프레임(dataframe)은 판다스의 핵심 데이터 구조이다. 다중 회귀에서 특성이 많을 때, 늘어난 데이터를 복붙하는 것은 굉장히 번거롭다. 그렇기 때문에 판다스를 이용하여 쉽게 넘파이 배열 또는 다차원 배열로 손쉽게 바꾸면 삶이 윤택해질 것이다.
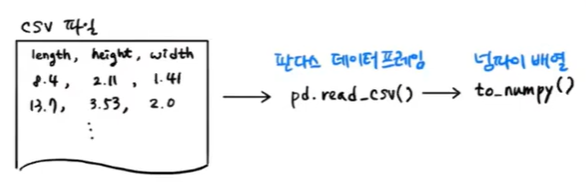
read_csv() 함수에 데이터 주소를 넣고 데이터프레임을 만든다. 그 다음에 to_numpy() 메소드를 사용하여 넘파이 배열로 바꾸면 된다.
import pandas as pd
df = pd.read_csv('https://bit.ly/perch_csv_data') #데이터프레임 만들기
perch_full = df.to_numpy() #넘파이 배열로 변환
print(perch_full)💡사이킷런 API의 세 가지 유형
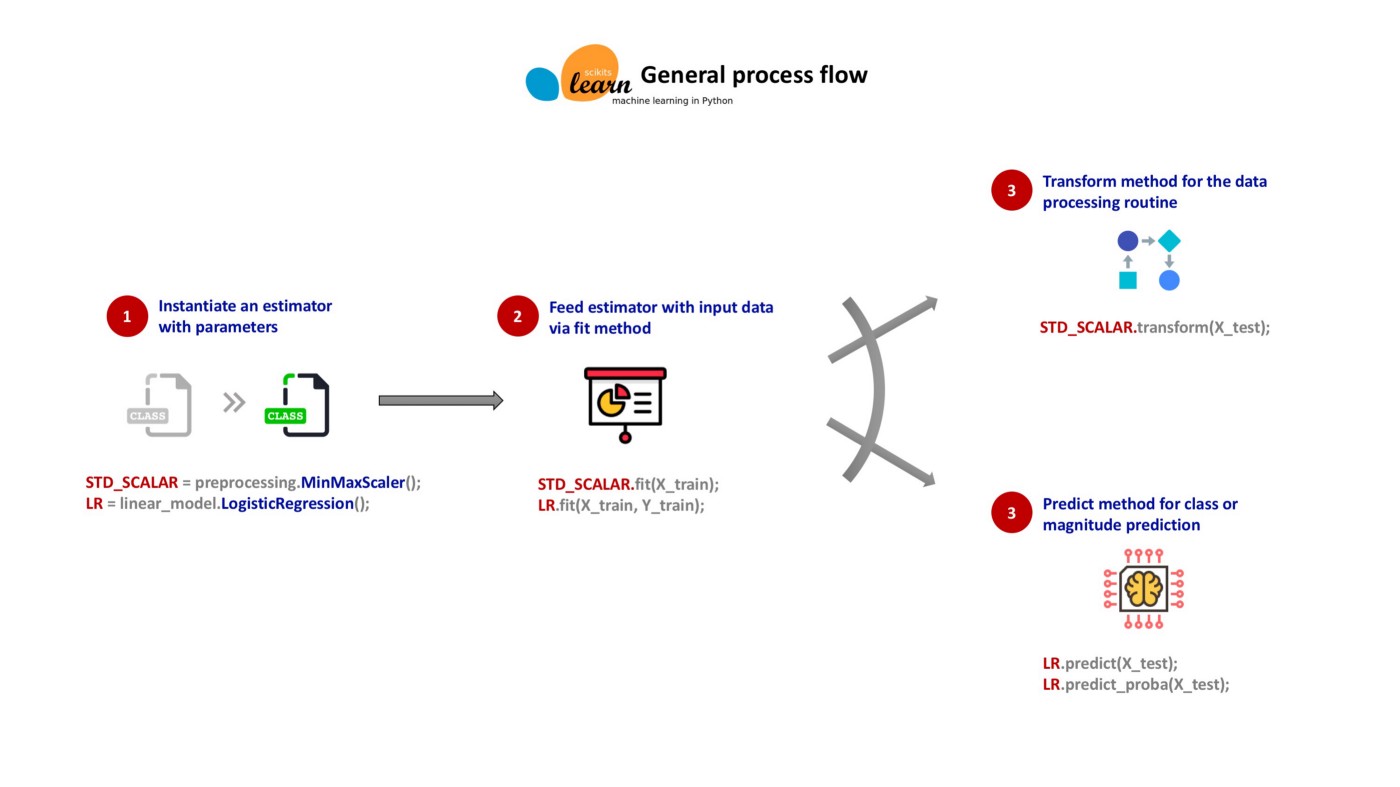
1️⃣추정기(estimator)
- 주어진 데이터셋과 관련된 특정 파라미터 값들을 추정하는 객체
- fit() 메서드 활용: 특정 파라미터 값을 저장한 속성이 업데이트된 객체 자신 반환
2️⃣변환기(transformer)
- fit() 메서드에 의해 학습된 파라미터를 이용하여 주어진 데이터셋 변환 transform() 메서드 활용
- fit() 메서드와 transform() 메서드를 연속해서 호출하는 fit_transform() 도 활용 가능
3️⃣예측기(predictor)
- 주어진 데이터셋과 관련된 값을 예측하는 기능을 제공하는 추정기
- predict() 메서드 활용
- fit() 과 predict() 메서드가 포함되어 있어야 함
- predict() 메서드가 추정한 값의 성능을 측정하는 score() 메서드도 포함
- 일부 예측기는 추정치의 신뢰도를 평가하는 기능도 제공
[코드]
사이킷런의 변환기
#사이킷런의 변환기
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(include_bias=False) #절편을 위한 항 제거
poly.fit(train_input)
train_poly = poly.transform(train_input) #훈련 세트 훈련 및 변환
print(train_poly.shape)
#(42, 9)
poly.get_feature_names() #피쳐 엔지니어링 조합 확인
#['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2']
test_poly = poly.transform(test_input) #훈련세트에 적용했던 변환기로 테스트 세트 변환
print(test_poly.shape)
#(14, 9)다중 회귀 모델 훈련하기 (과대적합 문제)
55개의 특성이 의미하는 바 : 샘플 개수보다 특성이 많다 → 과대적합 문제.
#다중 회귀 모델 훈련하기
from sklearn.linear_model import LinearRegression #선형회귀
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target)) #훈련 세트 score 출력
#0.9903183436982124
print(lr.score(test_poly, test_target)) #테스트 세트 score 출력
#0.9714559911594132
#테스트 세트에 대한 점수를 높이기 위해 특성 추가
poly = PolynomialFeatures(degree=5, include_bias=False) #degree 매개변수 사용 : 최대 차수 결정
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)
print(train_poly.shape)
#(42, 55) 55개의 특성 확인#훈련세트에 비해 테스트 세트의 점수는 음수 -> 과대적합
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
#0.9999999999991096
print(lr.score(test_poly, test_target))
#-144.40579242335605[참고자료]
특성공학에 대해서 한국어로 설명되어있음. 간단하게 설명되어 있어서 가볍게 읽기 좋다.
https://itwiki.kr/w/%ED%8A%B9%EC%84%B1_%EA%B3%B5%ED%95%99
특성 공학 - IT위키
itwiki.kr
특성공학 이미지 사용, 자세한 설명.
https://www.javatpoint.com/feature-engineering-for-machine-learning
Feature Engineering for Machine Learning - Javatpoint
Feature Engineering for Machine Learning with Tutorial, Machine Learning Introduction, What is Machine Learning, Data Machine Learning, Machine Learning vs Artificial Intelligence etc.
www.javatpoint.com
특성공학에 대한 자세한 설명. 바로 위의 자료와 병행해서 읽어도 괜찮다.
Discover Feature Engineering, How to Engineer Features and How to Get Good at It
Feature engineering is an informal topic, but one that is absolutely known and agreed to be key to success in […]
machinelearningmastery.com
한국어로 되어있어서 읽기 편함.
https://velog.io/@guide333/%EC%95%84%EC%9D%B4%ED%9A%A8-Feature-Engineering
[아이효] Feature Engineering
이 포스팅은 스터디 준비하면서 만든 자료를 정리한 것입니다. Feature Engineering을 잘 표현한 문장이다. Feature Engineering은 데이터 분석에서 많은 지분을 차지하는 부분이다.
velog.io
특성공학의 필요성에 대해서 잘 설명해주신다.
http://www.incodom.kr/%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5/feature_engineering
기계학습/feature engineering - 인코덤, 생물정보 전문위키
# feature engineering
www.incodom.kr
다중선형회귀 이미지 참고
https://hleecaster.com/ml-multiple-linear-regression-example/
다중선형회귀(Multiple Linear Regression) - 파이썬 코드 예제 - 아무튼 워라밸
파이썬 scikit-learn으로 다중선형회귀(Multiple Linear Regression) 분석하는 방법을 코드 예제와 함께 살펴보자.
hleecaster.com
사이킷런의 API 세 가지 유형 참고
https://codingalzi.github.io/handson-ml2/slides/handson-ml2-02b-slides.pdf
다중선형회귀에 대해서 쉽게 설명되어있다. + 라쏘
선형회귀(linear regression), 라쏘(LASSO), 리지(Ridge)
선형 회귀는 사용되는 특성(feature)의 갯수에 따라 다음과 같이 구분된다. - 단순 선형 회귀(simple linear regression) : 특징이 1개 - 다중 선형 회귀(multiple linear regression) : 특징이 여러개 LASSO와 Ri..
otugi.tistory.com
라쏘와 릿지에 대해 더 자세히 알고싶다면?
https://sanghyu.tistory.com/13
Regularization(정규화): Ridge regression/LASSO
이 강의를 보고 정리한 내용이고 자료도 강의에서 가져온 자료임을 밝히고 시작한다. 이전 포스팅에서 살펴본 linear regression 모델을 다시 살펴보자. 이렇게 least square solution을 구하면 너무 모델
sanghyu.tistory.com
Ridge regression(릿지 회귀)와 Lasso regression(라쏘 회귀) 쉽게 이해하기
Ridge regression와 Lasso regression를 이해하려면 일단 정규화(regularization)를 알아야합니다. 첫번째 그림을 보면 직선 방정식을 이용하여 선을 그었습니다. 데이터와 직선의 차이가 꽤 나네요. 정확한
rk1993.tistory.com
'Study > AI & ML' 카테고리의 다른 글
| 회귀 알고리즘과 모델 규제(2) - 선형 회귀 (4) | 2024.03.15 |
|---|---|
| 회귀 알고리즘과 모델 규제(1) - K-최근접 이웃 회귀 (3) | 2024.03.15 |
| 나의 첫 머신러닝&데이터 다루기 (3) (1) | 2024.03.15 |
| 나의 첫 머신러닝&데이터 다루기 (2) (0) | 2024.03.15 |
| 나의 첫 머신러닝&데이터 다루기 (1) (0) | 2024.03.15 |



