Distributed system에서 여러 컴퓨터가 하나의 시스템처럼 동작하기 위해서 Consensus Algorithm 등장
- Fail-Stop : 단순히 노드가 고장나서 멈추는 형태
- Fail-Stop 형태의 장애를 가정한 대표적인 consensus algorithm이 Paxos, Raft
- Byzantine Failure : 고장나서 멈추는 것 + 노드가 악의적인 행동을 포함한 임의의 동작을 할 수 있는 문제
- 대표적인 consensus algorithm이 PBFT(Practical Byzantine Fault Tolerance)
Paxos란?
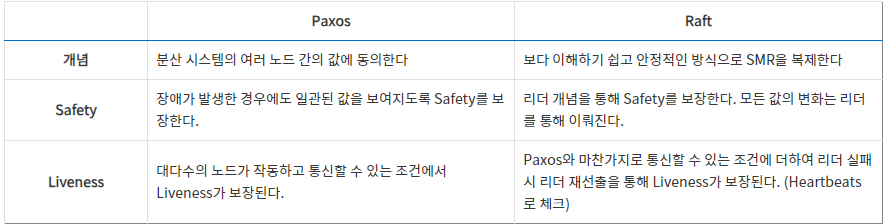
분산 시스템에서 여러 프로세스 간에 하나의 값에 동의하기위한 프로토콜.
- proposer, accepter, learner → 이 3개의 역할로 구분된다.
- proposer가 제안하면 accepter가 받을까 말까 고민하고, 과반수 이상이 동의하면 그 값에 대해 모두 공유한다.
- 즉, Paxos 알고리즘의 목표는 단 하나의 consensus를 이루는 것이다.
단점 : 프로토콜의 동작이 복잡하여 구현이 어렵다.

Raft란?
Paxos 알고리즘에서 한 번의 consenses를 이루는 절차가 꽤나 복잡하고 구현이 어렵다는 문제가 있다.
해결방안 : USENIX ATC 2014에서 <In Search of an Understandable Consensus Algorithm>라는 논문 발표를 통해 Raft 알고리즘 등장
- leader, follower, candidate → 모든 노드들은 세 가지 상태 중 하나를 가짐 (Paxos와 다르게 고정된 역할이 없다.)
- Leader election : RPC 프로토콜(AppedEntries)를 통해 살아있음을 알림 → timeout 동안 신호를 받지 못하면 반란 → 투표 진행
- 저장된 임기번호(term)을 1증가시키고 새로운 선거를 진행한다.
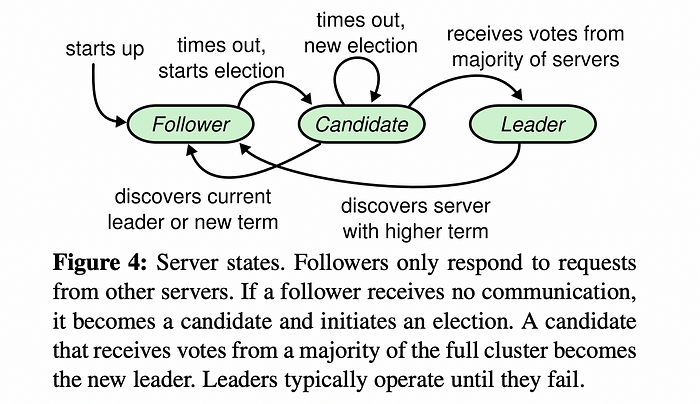
- Log Replication : 리더가 정해지고 나서는 시스템의 모든 변경사항이 리더를 통하게 된다. 각 변경사항은 Log Entries에 저장되고 다른 follower들에게 복제된다.
- Log Entry : Term(임기), Index(log 저장할 때의 번호), Data
- Client가 leader에거 변경사항을 보낸다. → 변경사항은 leader의 log entry에 저장 → RPC 호출을 통해 log 전달 → Follower들은 새로받은 log를 저장하고 성공 응답

Conclusion
References.
https://gruuuuu.github.io/integration/paxos-raft/
호다닥 톺아보는 합의 알고리즘 : PAXOS, RAFT
Distributed System과 Consensus Algorithm 싱글 컴퓨터로는 성능의 향상에 있어 제한이 있습니다. 만약 해당 컴퓨터에 장애가 발생한다고 한다면 꼼짝없이 돌아가던 서비스도 멈추게 될거고요. 그래서 복
gruuuuu.github.io
Paxos보다 쉬운 Raft Consensus
이해 가능한 합의 알고리즘을 위한 여정
medium.com
https://loosie.tistory.com/890
분산 데이터베이스 탐구: 합의 알고리즘 (Paxos, Raft, PBFT, PoW)
분산 데이터베이스 탐구: 합의 알고리즘이전 글에서 분산 시스템에서 데이터 일관성 문제와 관련된 문제를 어떻게 해결하는 로컬 트랜잭션과 분산 트랜잭션, 충돌 회피 또는 충돌 감지 및 해
loosie.tistory.com
'연구 > 주제 없음' 카테고리의 다른 글
| Optimizing AI/ML and HPC Workloads: Exploring RDMA (RoCEv2) for High-Performance (0) | 2024.09.06 |
|---|---|
| [TIL] Consistency Models for concurrent systems (0) | 2024.07.16 |
| [TIL - 20240704] RDMA Atomic operation이란? (0) | 2024.07.04 |
| [TIL - 20240703] Turing complete란? (1) | 2024.07.03 |

